LLM sử dụng tool như thế nào?
Bản thân LLM không có khả năng "sử dụng tool", theo nghĩa đen, tức là thực hiện lời gọi trực tiếp tới tool/function. Vì về bản chất, LLM chỉ là một cái text generator, nó dự đoán và đưa ra ra token tiếp theo dựa trên những token input trước đó.
Đa số các LLM agent thực hiện việc gọi tool bằng cách generate ra lời gọi ở dạng text hoặc JSON, ví dụ:
- Gọi tool bằng text (cú pháp gì cũng đc, tuỳ client xử lý, đại ý ở đây là nó sẽ gen ra
tên-tool+arguments):
web_search, "blog thefullsnack còn update không?"
- Gọi tool bằng JSON (tương tự như text nhưng ở định dạng JSON cho dễ parse)
<tool>
{"tool": "web_search", "arguments": "{\"query\": \"huytd đẹp trai ko\"}"}
</tool>
Khi chúng ta sử dụng LLM thông qua API của các provider như OpenAI, hoặc ở local như Ollama, LM Studio, chúng ta không tương tác trực tiếp với LLM đó, mà thông qua một lớp nằm giữa, tạm gọi là một chiếc API controller.
API controller này có nhiệm vụ convert request gửi lên từ user, thành input token, với định dạng phù hợp với model được chọn, thực hiện inference, và convert output tokens từ LLM về đúng định dạng trả về của API.
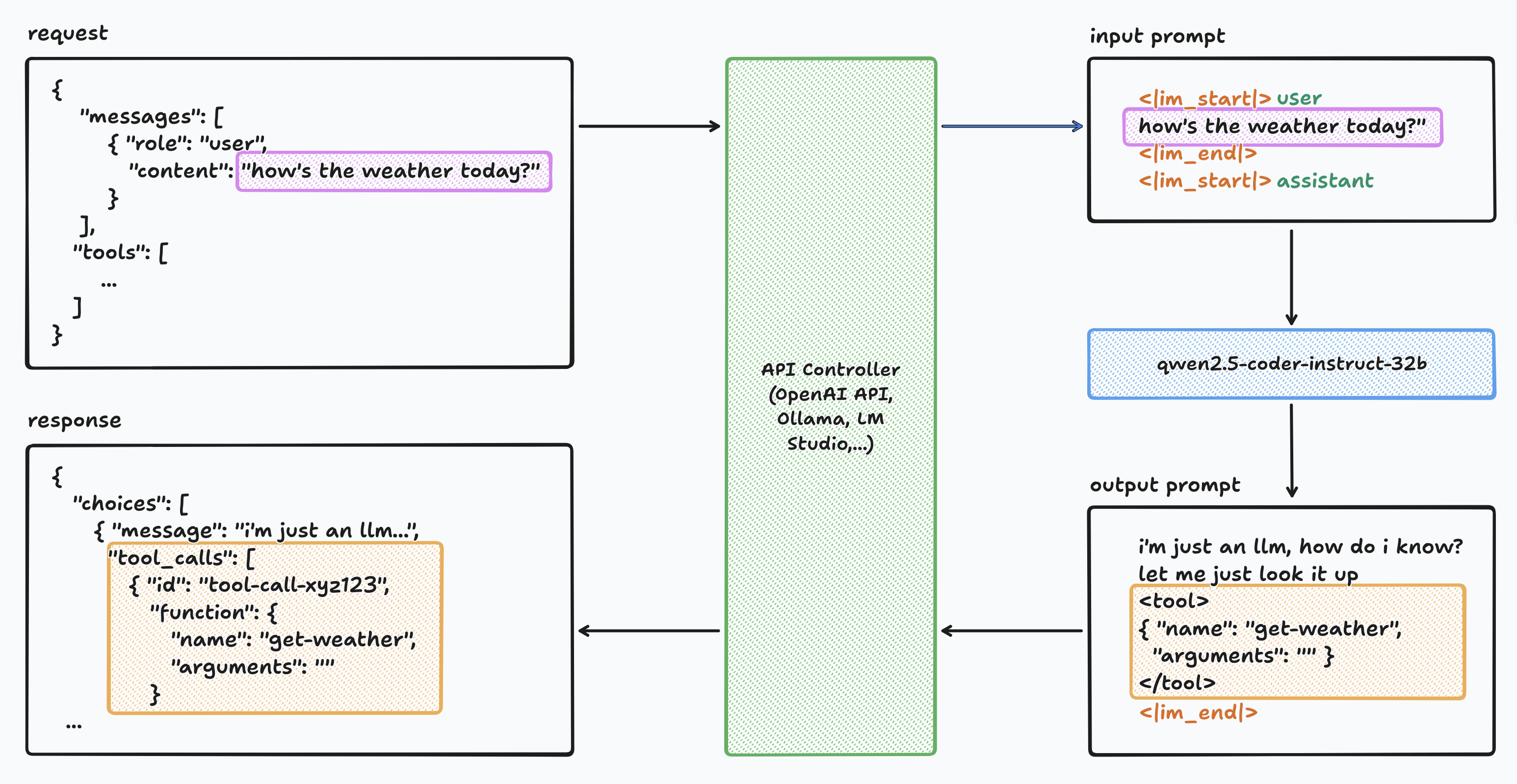
Lời gọi tool generate ra từ LLM (ở định dạng text hoặc JSON) cũng sẽ được API controller parse và đưa vào response payload.
Như vậy, để có thể implement được một LLM agent biết sử dụng tool, chúng ta cần 2 yếu tố:
- Model đang sử dụng phải được train để biết cách nhận biết khi nào thì nó cần sử dụng tool, và biết cách generate ra lời gọi tool đúng cú pháp.
- API controller mà bạn làm việc cùng phải biết cách parse và convert lời gọi tool từ LLM thanh payload hợp lý trong APi response.
Đa số các frontier LLM như OpenAI, Claude, Gemini đều thoả mãn cả 2 yếu tố trên. Nhưng đôi khi chúng ta chỉ có một trong 2 yếu tố, hoặc không có cái nào cả. Ví dụ như nhiều model không được trained để sử dụng tool (qwen2.5-coder), trong khi nhiều model khác thì có (qwen2.5-instruct). Hoặc một số API provider không hỗ trợ tool (hầu hết các free API provider, hoặc các free model trên OpenRouter,...).
Yếu tố thứ nhất (model không biết cách gọi tool), có thể được chữa cháy bằng prompt engineering, tức là hướng dẫn model biết cách generate ra lời gọi tool theo đúng format, ở trong system prompt. Đây là cách mà phần lớn model trên Ollama sử dụng, chúng ta có thể thấy khi nhìn vào template của một model, ví dụ qwen2.5-coder-tools:
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
{{- end }}<|im_end|>
{{ end }}
...
<|im_start|>assistant
{{ if .Content }}{{ .Content }}
{{- else if .ToolCalls }}<tool_call>
{{ range .ToolCalls }}{"name": "{{ .Function.Name }}", "arguments": {{ .Function.Arguments }}}
{{ end }}</tool_call>
{{- end }}{{ if not $last }}<|im_end|>
{{ end }}
Nhược điểm của cách này là, vì model chưa được train nên tỉ lệ nó generate ra lời gọi tool sai format khá cao.
Khi yếu tố thứ hai không xảy ra (API controller không hỗ trợ tool), thì có thể giải quyết bằng cách không thực hiện gọi tool theo API nữa, mà client sẽ phải tự implement logic nhận biết tool call. Ví dụ như trong dự án SuperCoder, mình sử dụng cách này, để support tool calling cho mọi model/provider.
Ngoài hai phương pháp text-based và JSON-based tool calling đã nói ở trên, vào năm 2024, có một phương pháp mới được giới thiệu đó là Code-based tool calling, gọi là CodeAct. Các bạn có thể đọc thêm tại https://arxiv.org/pdf/2402.01030
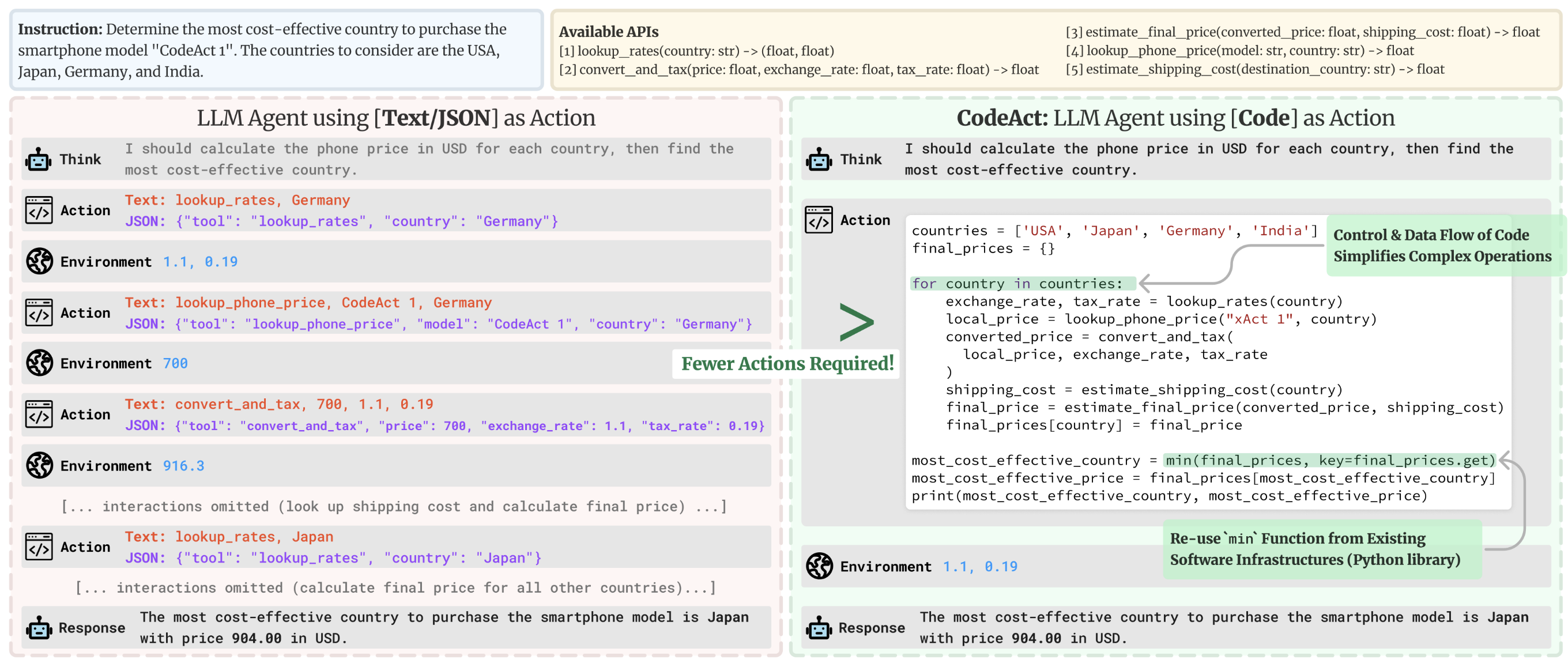
Hiểu đơn giản thì, nếu LLM cần thực hiện một loạt nhiều tool call nối tiếp nhau, ở phương pháp sinh text hoặc JSON, model sẽ phải chờ phía client thực hiện từng tool một, trả về kết quả rồi generate ra lời gọi tool khác, tốn rất nhiều bước, thì với phương pháp CodeAct, LLM có thể tự generate ra một đoạn code dùng để gọi tất cả các tool cần thiết, theo quy trình cần thiết, rồi để cho phía client execute đoạn code đó một lần.
Cách này được cho là nâng tỉ lệ thành công khi thực hiện task của nhiều model lên đến 20%, và tốn ít thời gian hoàn thành task hơn.
Hiện tại có smolagents, thư viện build Agents của HuggingFace, là implement phương pháp này.