Side-project ký sự: Teaching LLM a Niche Language
Bài viết này được dịch từ bài gốc tiếng Anh của cùng tác giả, lý do? Vì tác giả rảnh. Bạn có thể đọc bài gốc tại đây.
Text-to-diagram có vẻ như đã được mấy con LLM giải quyết ngon lành cành đào rồi, nhưng ngặt nỗi chỉ loanh quanh mấy cái phổ biến như Mermaid hay PlantUML. Còn mấy món lạ lạ (niche) như D2, Structurizr hay Pintora thì coi bộ hơi khoai. Mình muốn thử xem có thể dạy LLM học mấy ngôn ngữ này đến đâu, và mình chọn Pintora làm chuột bạch, vì chắc chắn mấy model nhỏ (small models) chưa được học cái này bao giờ.
Mục tiêu (Project Goal)
Vậy mục tiêu cụ thể là gì? Mình muốn train một con LLM có khả năng xào nấu Pintora diagram, cụ thể là:
- Generate diagram từ con số 0.
- Edit bất kỳ diagram nào có sẵn.
Chọn mặt gửi vàng (The Base Model)
Mình giới hạn scope ở các model dưới 30B thôi, tiền đâu mà train mấy con to hơn.
Sau khi test thử mấy con 4B trở xuống thì thấy hơi "ngu", không phù hợp lắm cho task code-generating hoặc follow instruction trong hội thoại dài. Tầm 7B-14B là đẹp. Mình cũng ưu tiên base trên mấy con coding model cho nó code-smart một tí.
Gemma-3 thì cỡ lỡ cỡ (4B với 27B). Codestral bé nhất cũng 22B. Ministral 3 thì lúc viết bài này chưa ra. Qwen3 thì mình không muốn dính dáng tới cái thinking mode lằng nhằng nên cũng bỏ qua. Sau một hồi đắn đo thì chốt đơn: Qwen2.5-Coder-7B. Ở năm 2025 thì con này chắc thuộc hàng "cổ đại" tính theo lịch LLM rồi, nhưng kệ, xài tốt là được.
Để chắc ăn là con Qwen2.5 này chưa biết gì về Pintora, mình thử prompt:
create a pintora component diagram for a website like twitter
Và y như rằng, nó phọt ra một cái diagram rất xịn sò... bằng PlantUML:
Below is a component diagram using Pintora syntax. You can copy and paste this into a Pintora editor to visualize it.
@startuml
!define RECTANGLE class
title Twitter Component Diagram
RECTANGLE "User Interface" as UI {
RECTANGLE "Header" as Header
RECTANGLE "Footer" as Footer
...
Kế hoạch training
Vì dạy ngôn ngữ mới nên phải chia làm 2 giai đoạn:
- Phase 1: Continued Pretraining (CPT) - Ném cho model một đống Pintora diagram để nó học syntax, nhận diện cấu trúc ngữ pháp các kiểu.
- Phase 2: Instruction Finetune (IFT) - Sau đó mới dạy nó làm theo instruction để generate/edit diagram dựa trên kiến thức đã học.
Mình dùng training notebook của Unsloth cho lẹ, nó support 4-bit quantized LoRA nên train nhanh và ít tốn VRAM hơn.
Chuẩn bị "cơm gạo" (Data Preparation)
Đầu tiên là phải có dataset dùng cho cả 2 phase CPT và IFT. Mình nhắm chừng cần khoảng 1000-1500 dòng là đủ (minimum viable dataset).
Pintora support đủ thứ loại: Sequence, ER, Component, Activity, Mindmap, Gantt, Class,... Mỗi loại làm tầm 150-200 mẫu để data đa dạng.
Mình muốn model có khả năng generate hoặc edit, nên dataset cần có các mẫu bao gồm cả diagram input (cho trường hợp edit).
Plan là mỗi dòng data sẽ có 3 trường:
- instruction: mô tả user muốn vẽ cái gì.
- input: diagram input (optional, dùng khi edit).
- output: code diagram hoàn chỉnh mà model cần generate.
Lên plan xong xuôi, mình bắt đầu ngồi gõ tay từng dòng... được tầm 5 dòng thì dẹp. Manual labor kiểu này chắc tới tết Congo mới xong!
Lên Github lục lọi xem có code sẵn không thì cũng chỉ có lèo tèo 5-6 cái repo. Mà chôm code người ta cũng kỳ, chưa kể hỏi permission chắc gì họ đã rep.
Cuối cùng: Lại lôi AI ra generate data! Bí kíp ở đây là viết cái prompt siêu chi tiết, ném hết doc syntax và example vào. Sau đó là chuỗi ngày năn nỉ ỉ ôi con AI agent cứ mỗi 50 entries, dọa nó là Godzilla ngoài hành tinh sẽ phá nát cầu Cổng Vàng nếu nó không làm xong việc.
Kết quả thu được sau khi đi xin xỏ là tầm 2000 entries. Nhưng mà chán đời lắm, cả Gemini 3 Pro lẫn Claude Sonnet 4.5 đều generate sai syntax tùm lum, duplicate cũng nhiều.
Mình phải viết script để merge mấy dòng trùng output, rồi chạy @pintora/cli để render thử từng dòng, cái nào lỗi thì vứt.
Chốt lại sau khi lọc thì còn 1000 dòng cho CPT và 500 dòng cho IFT. Anh em nào cần thì mình để link Hugging Face ở cuối bài.
Quá trình Training
Mới đầu hí hửng chạy trên Google Colab (1 T4 16GB) thì bị OOM (Out Of Memory) ngay lập tức. Qua Kaggle (2xT4) cũng không khá hơn. Thế là phải cắn răng thuê con A40 48GB trên Runpod, giá $0.4/h.
Tính ra con 7B chạy 4-bit QLoRA mà cái training script của mình nó ngốn tới 19.33GB VRAM, bảo sao T4 chịu không nổi (thực tế VRAM available của T4 trên Colab còn ít hơn 16GB). Nhưng ngẫm lại thì đây là vấn đề không đáng có.
Về lý thuyết, Pintora keywords cũng toàn tiếng Anh quen thuộc, model không cần học token mới. Đáng lẽ mình có thể tiết kiệm được 5-6GB VRAM cần thiết nếu bỏ embed_tokens và lm_head ra khỏi target_modules.
model = FastLanguageModel.get_peft_model(
model,
r = 64,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
"embed_tokens", "lm_head", # could have removed this
],
lora_alpha = 64,
lora_dropout = 0.05,
use_gradient_checkpointing = "unsloth",
...
)
Quay lại việc training. Sau khi xong phase CPT, mình test thử xem nó học hành ra sao:

Có vẻ bắt đầu hiểu syntax của Pintora rồi đấy, dù code vẫn sai lè.
Tiếp theo mình load cái pintora-edit-instruct dataset vào để chạy phase IFT, với format prompt như sau:
edit_prompt = """Pintora Diagram Edit Instruction
### Instruction:
{instruction}
{input}
### Response:
{output}
"""
Sau bước này thì model khôn ra hẳn, code chuẩn chỉ và chính xác hơn nhiều, cho cả task generate từ đầu lẫn edit.
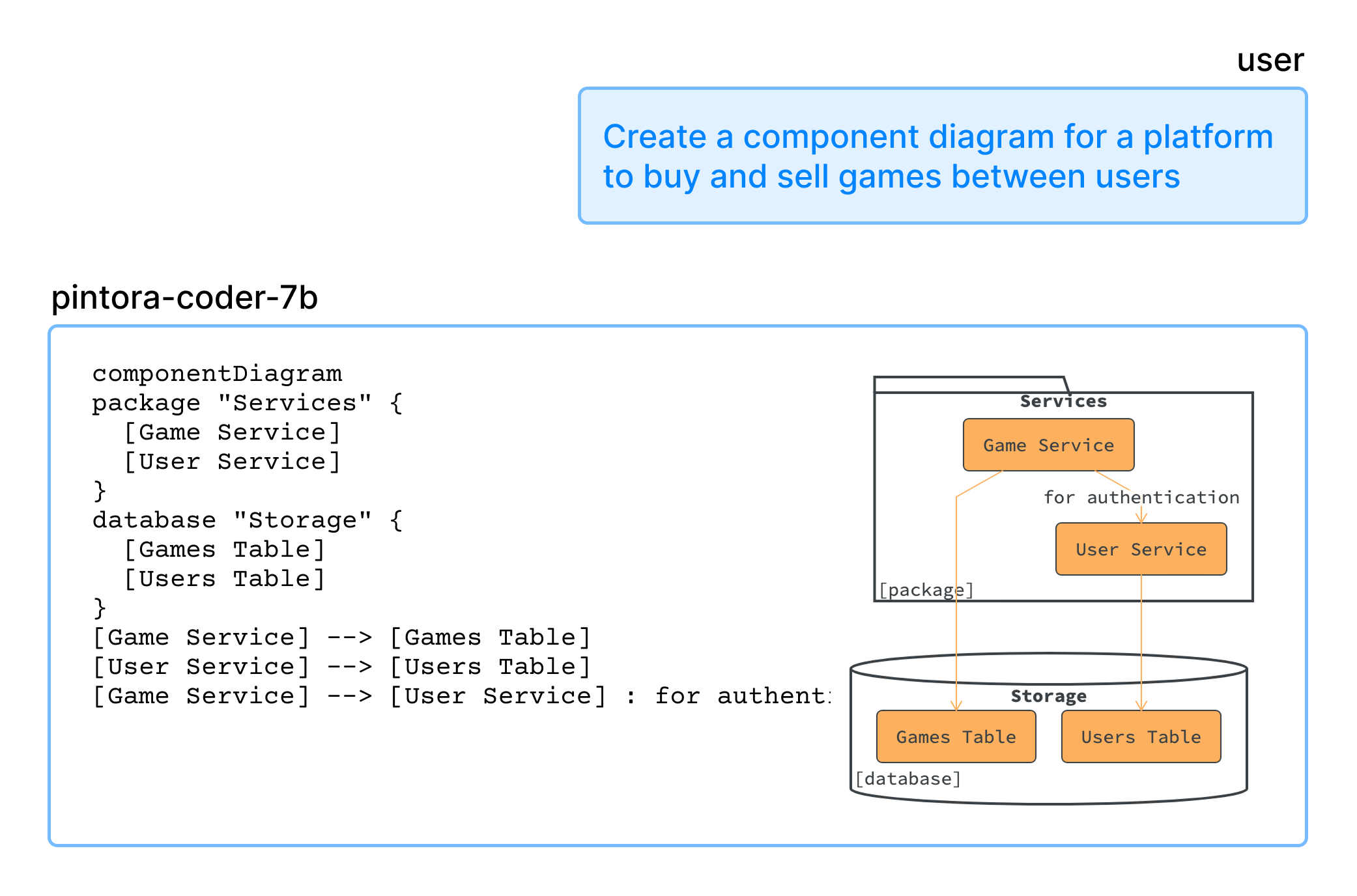
Generate diagram from scratch
Editing existing diagram
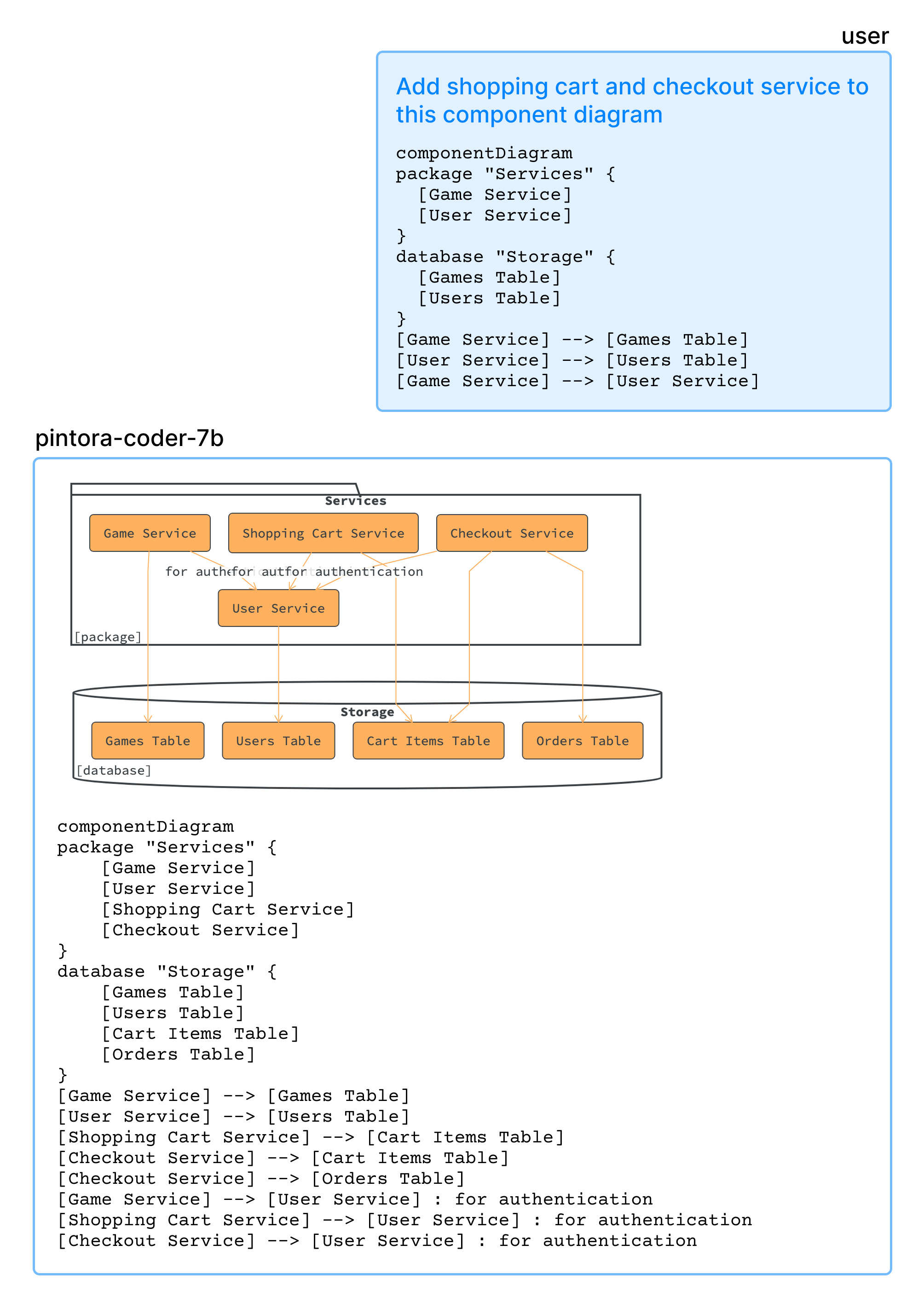
Tới đây là coi như thành công dạy Qwen2.5-Coder vẽ Pintora thay vì phọt ra mấy cái Mermaid/PlantUML random rồi. Giờ check xem nó học "giỏi" cỡ nào.
Chấm điểm (Evaluation)
Để check nhanh accuracy của diagram được tạo ra (chưa bàn tới chất lượng/thẩm mỹ), mình ~~vibed~~ viết một đoạn script để generate random prompt:
...
entities = [
'User', 'Client', 'WebApp', 'Backend', 'Server', 'Database', 'AuthService',
'PaymentGateway', 'Cache', 'Redis', 'Worker', 'TaskQueue', 'Frontend',
'API Gateway', 'OrderSystem', 'Inventory', 'NotificationSvc', 'Logger', 'MetricsSvc'
]
actions = [
'requests login', 'fetches data', 'updates record', 'processes payment',
'validates token', 'sends email', 'renders view', 'queries index',
'health check', 'ack signal', 'authenticates user', 'writes to log',
'queries for user profile', 'returns 200 OK', 'returns 404 Not Found',
'submits form', 'enqueues job', 'dequeues job', 'generates report'
]
diagram_types = ['sequenceDiagram', 'componentDiagram', 'activityDiagram']
def create_from_scratch_task():
d_type = random.choice(diagram_types)
num_interactions = random.randint(1, 3)
interactions = []
for _ in range(num_interactions):
src, dst = random.sample(entities, 2)
action = random.choice(actions)
interactions.append(f"{src} {action} to {dst}")
prompt_desc = ", and then ".join(interactions)
instruction = f"Create a {d_type} that shows: {prompt_desc}."
output_code = model.generate(instruction)
return [instruction, "", output_code]
for i in range(1000):
create_from_scratch_task()
...
Ví dụ một vài kết quả:
| instruction | input | output |
|---|---|---|
| Create a activityDiagram that shows: PaymentGateway returns 404 Not Found to... | activityDiagram start :Worker requests PaymentGateway; if (PaymentGateway returns 404)... | |
| Add a step where User health check to MetricsSvc. | sequenceDiagram Cache->>User: enqueues job | sequenceDiagram Cache->>User: enqueues job User->>MetricsSvc: health check |
| Add a step where PaymentGateway health check to Inventory. | sequenceDiagram Worker->>PaymentGateway: enqueues job | sequenceDiagram Worker->>PaymentGateway: enqueues job PaymentGateway->>Inventory: health check |
Sau đó dùng lại chiêu cũ lúc làm data: deduplicate rồi parse từng cái output bằng lệnh @pintora/cli.
Kết quả: Trong 996 diagrams thì có 139 cái lỗi syntax, 857 cái render ngon lành. Accuracy tầm 86%, quá ổn áp cho một lượng training data ít ỏi như vậy.
Kết
Lần experiment này học được khối thứ, sai cũng nhiều chỗ đáng lẽ làm tốt hơn được, nhưng mà vui. Chắc đợt tới thử tackle cái accuracy bằng RL (Reinforcement Learning) xem sao, nghe đồn món này ảo ma lắm, khen chê đủ cả nên phải thử mới biết.
Mình cũng đang nghía cái ngôn ngữ lập trình âm nhạc Strudel, train LLM món này chắc cũng thú vị.
Link model (có GGUF) và dataset cho anh em nào cần vọc vạch, kèm file kết quả eval bên dưới:
Model:
- https://huggingface.co/huytd189/pintora-coder-7b
- https://huggingface.co/huytd189/pintora-coder-7b-gguf (GGUF - F16, Q8, Q4_K_M)
Dataset:
- https://huggingface.co/datasets/huytd189/pintora-instruct
- https://huggingface.co/datasets/huytd189/pintora-edit-instruct
Eval result: