Side-project ký sự: Phân loại hình ảnh ngay trên trình duyệt
TLDR: Bài viết này kể về cách mình xây dựng chức năng phân loại hình ảnh, giúp cho user phát hiện và tránh được việc up nhầm ảnh cá nhân không mong muốn. Việc kiểm tra/phân loại diễn ra hoàn toàn ở phía client, bảo đảm cho dữ liệu của user không bao giờ bị lộ ra ngoài.
Giải pháp ban đầu sử dụng một model có sẵn, dựa trên kiến trúc Vision Transformer, đạt độ chính xác 76.9%, tuy nhiên gặp phải một số nhược điểm như dung lượng nặng và tốc độ xử lý chậm, việc tinh chỉnh diễn ra một cách thủ công và mang tính thử sai nhiều hơn là kĩ thuật, nên mình chọn cách tự train (finetune) một model mới dựa trên kiến trúc MobileNetV3.
Kết quả độ chính xác tăng lên 80%, thời gian xử lý trung bình giảm từ 550ms xuống còn 20ms, dung lượng model giảm từ ~350MB xuống còn 6MB.
Các bạn có thể xem demo trực tiếp tại:
Để nắm nội dung bài viết tốt hơn, các bạn có thể dành ra 1h để đọc bài viết PyTorch in One Hour của tác giả Sebasstian Raschka, bạn sẽ hiểu được cách Pytorch hoạt động, cách một model được train, những gì xảy ra trong training loop,...
Còn bây giờ chúng ta vào nội dung chính của bài viết nhé
Thực ra gắn tag side-project cho bài viết này cũng không hẳn là chính xác, nhưng mà kệ đi, quan trọng là có bài để post
Chuyện là thế này, mình làm việc tại một công ty chuyên về business travel và expense management, và mình đang thực hiện một dự án tích hợp mô hình ngôn ngữ lớn để nâng tầm trải nghiệm, giúp cho người dùng dễ dàng kê khai chi phí công tác một cách dễ dàng và tiện lợi hơn, a.k.a build một con LLM chatbot để giúp người dùng tạo expense một cách nhanh chóng.
Một trong những feature mà con chatbot này support đó là khả năng tự động kê khai chi phí từ thông tin ở trong một hoặc một vài file invoice/receipt mà người dùng gửi lên.
Nói đến đây thì bạn nào đã từng build app tích hợp với LLM (a.k.a LLM wrappers) chắc cũng sẽ hình dung được feature này hoạt động như thế nào, vầng, bọn mình chỉ đơn giản là gửi cái hình mà user up lên đến LLM API (ví dụ của OpenAI), để mô hình tự động trích xuất thông tin (OCR), trả về 1 cục JSON là thông tin của expense.
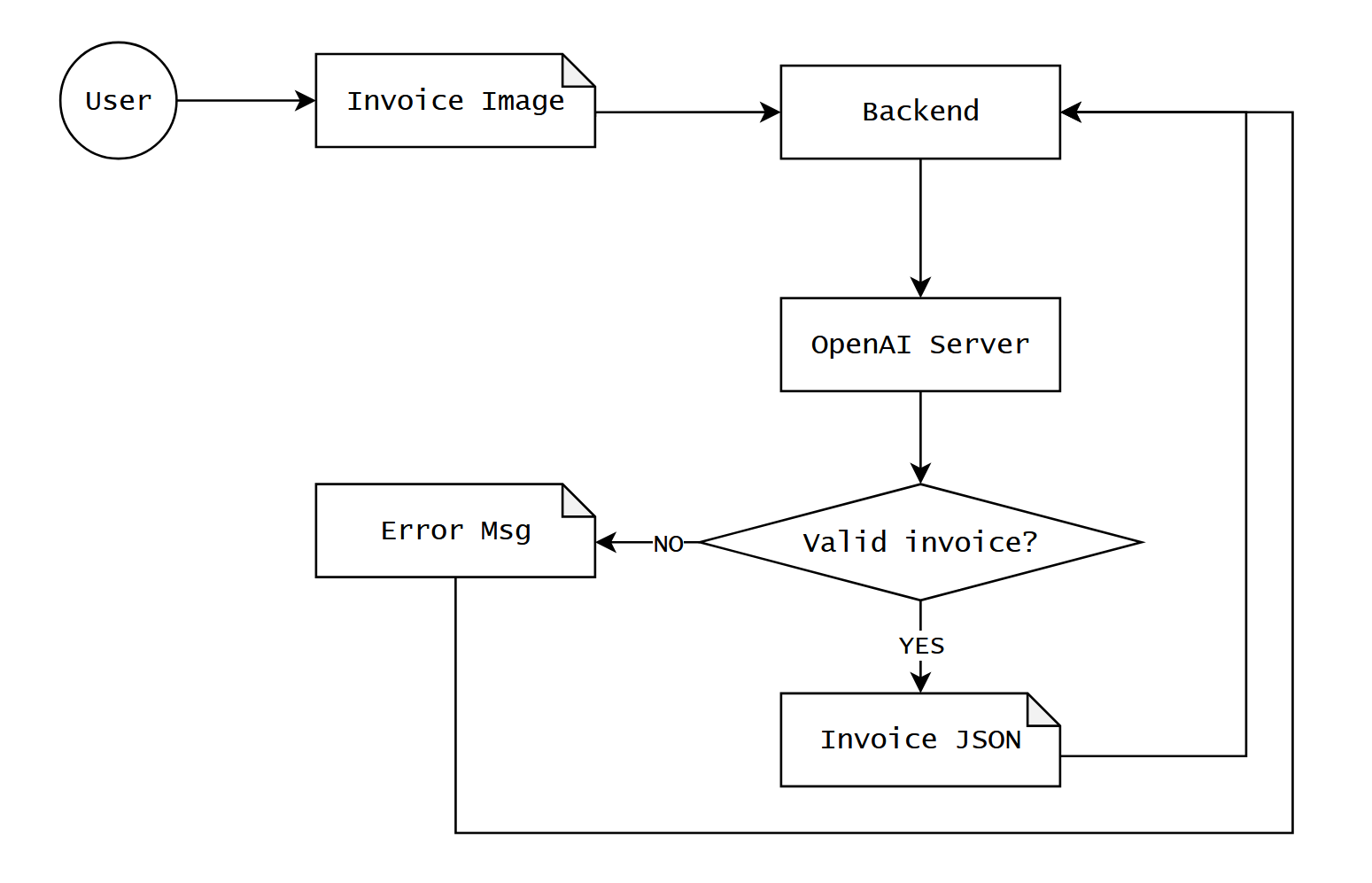
Nhưng nếu câu chuyện nó đơn giản như thế này thì mình chả cần viết bài này làm quái gì, và các bạn cũng chả cần phải đọc bài này để làm cái quái gì, đúng không?
Phức tạp hóa vấn đề
Sẽ thế nào nếu user vô tình chọn phải một tấm hình nhạy cảm nào đó để up lên, thay vì là một tờ hóa đơn hợp lệ? Ví dụ ảnh con mèo, hoặc một tấm ảnh selfie, hoặc một tấm ảnh selfie có con mèo?
Đứng ở vị trí của user, không ai muốn lỡ tay up nhầm ảnh đời tư của cá nhân mình hoặc một cá nhân khác lên một server nào đó liên quan đến AI hoặc là công việc, hoặc là cả 2. Đứng ở vị trí của công ty, không ai muốn dây dưa với việc dữ liệu nhạy cảm cá nhân của user xuất hiện trên server của mình, hoặc vô tình gửi dữ liệu đó sang một bên thứ 3. Đứng ở vị trí nhà cung cấp dịch vụ LLM, ai mà biết là họ sẽ làm gì với dữ liệu được gửi lên server của họ, mặc dù trong điều khoản sử dụng luôn có mục cam kết không sử dụng dữ liệu người dùng để train AI.
Nói tóm lại, là user không được phép up nhầm ảnh, tất cả ảnh up lên đều phải là một chiếc invoice/receipt, hoặc trông giống như thế.
Nhưng ở góc độ kĩ thuật, làm thế nào để bảo đảm user sẽ không up nhầm ảnh nếu chúng ta không up tấm ảnh đó lên server để check?
Client-side AI với Transformers.js
Transformers.js là thư viện được phát triển bởi Hugging Face, ban đầu được dùng để chạy những model transformer-based (cụ thể là LLM) ngay trên trình duyệt web, vậy nên nó mới có cái tên như vậy. Nhưng về sau thì càng nhiều model lớn nhỏ khác nhau được support, và tất nhiên là có cả các model non-LLM.
Với ImageClassificationPipeline của transformers.js, chúng ta có thể sử dụng một mô hình phân loại ảnh siêu nhỏ, đủ để chạy trực tiếp trên trình duyệt để kiểm tra tính hợp lệ của ảnh mà user định up lên.
![]()
Khi chạy, transformers.js sẽ tự động download model về trình duyệt của user, bước này chỉ xảy ra 1 lần, và ở các lần visit về sau, model sẽ được cache lại. Khi user cần upload một hình ảnh, chúng ta sẽ phân loại hình ảnh này ngay trên trình duyệt, và chỉ gửi lên backend nếu hình ảnh trên là invoice/receipt hợp lệ, ngược lại, chúng ta sẽ đưa ra một thông báo lỗi, và yêu cầu user kiểm tra lại hình ảnh đã chọn.
Cụ thể thì chúng ta có thể implement chức năng này với vài ba dòng code trên Frontend như này:
const classifier = await pipeline('image-classification', 'Xenova/vit-base-patch16-224');
const url = '<hình ảnh cần kiểm tra>';
const output = await classifier(url);
// Output của hàm `classifier()` ở trên sẽ có dạng:
// [
// { label: 'book', score: 0.632695734500885 },
// { label: 'cat', score: 0.3634825646877289 },
// { label: 'food', score: 0.00045060308184474707 },
// ...
// ]
const INVOICE_LABELS = [
'envelope', 'binder', 'notebook', 'packet', 'paper towel',
'web site', 'book jacket', 'rule', 'desk', 'file'
];
// Check nếu bất kỳ label nào nằm trong INVOICE_LABELS thì kết luận
// đây là invoice hợp lệ
const isValidInvoice = ...
Ở ví dụ trên, vit-base-patch16-224 là tên của một model phân loại hình ảnh của Google, model này vẫn dùng kiến trúc transformer, đã được convert qua định dạng ONNX để chạy trên web.
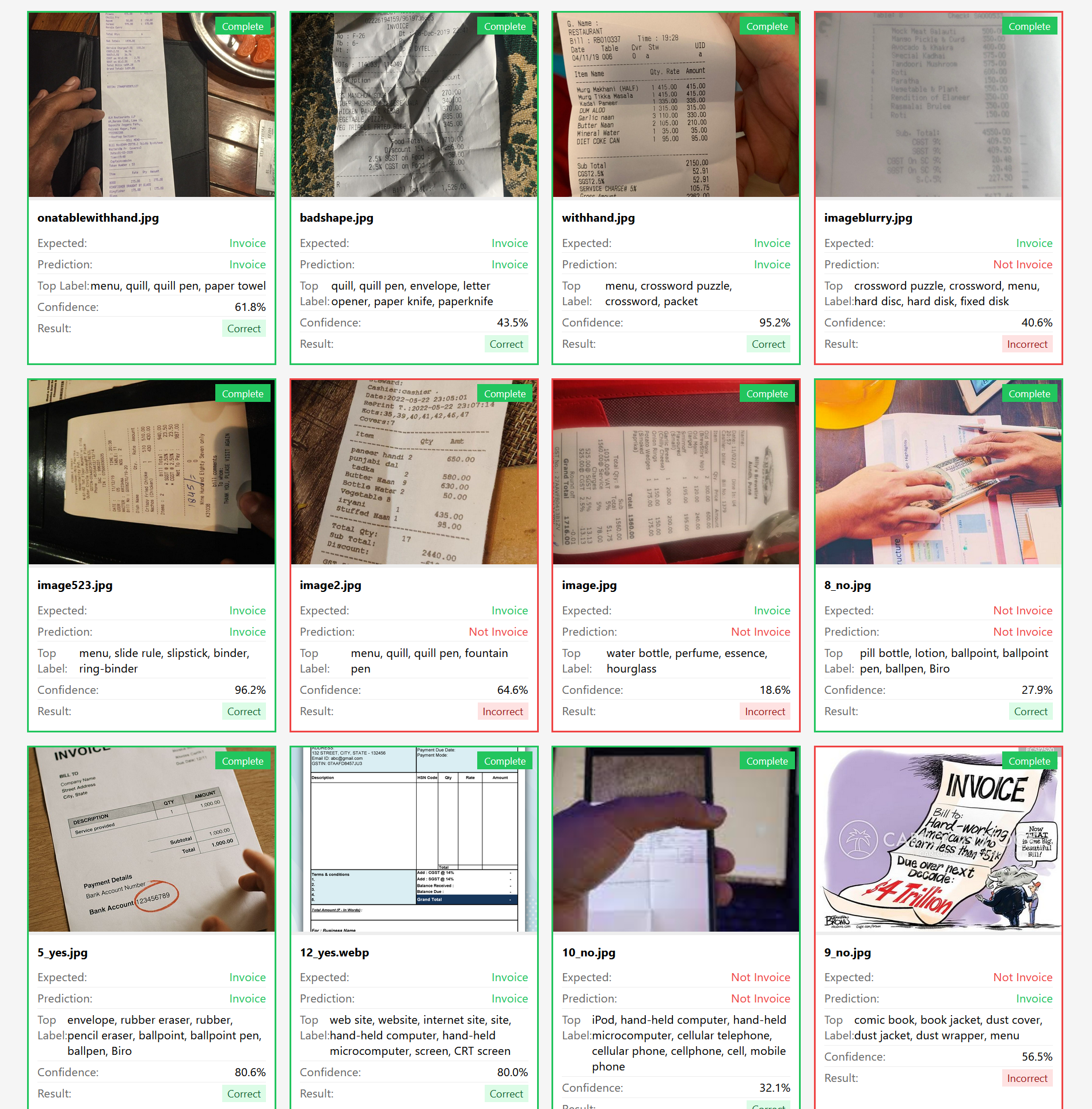
Sau khi team mình thử nghiệm với model trên thì có một vài vấn đề như sau:
- Kích thước model vẫn quá lớn, 347 MB cho bản full (f32), và phiên bản quantized nhỏ nhất là Q4 cũng có kích thước khoảng 50MB.
- Độ chính xác chỉ có 76%. Model được train để phân loại khoảng 1000 nhóm hình ảnh khác nhau, nghe thì có vẻ xịn, nhưng điều này đồng nghĩa với việc chúng ta cần phải maintain một danh sách các tên nhóm mà model có thể đưa ra (xem dòng Top Label ở screenshot trên), giống như mảng
INVOICE_LABELSở đoạn code trên. Việc chọn thêm/bớt một label vào mảng trên được thực hiện một cách thủ công, mang tính thử sai, không đáng tin cậy. - Thời gian trung bình để xử lý một hình ảnh là khoảng 550ms, tức là nửa giây, khá chậm, và trong trường hợp user up nhiều hơn 1 hình ảnh thì tốc độ xử lý còn chậm hơn rất nhiều.
Vấn đề thứ 2 có thể giải quyết được bằng cách tinh chỉnh mảng INVOICE_LABELS, tuy nhiên vấn đề thứ 1 và 3 thì không có cách nào khác để giải quyết, vì thế mình quyết định sẽ tự train một model phân loại hình ảnh riêng
Mô hình MobileNetV3
Tất nhiên là tay ngang như mình thì không đủ khả năng và kiến thức để tự xây dựng một ML model từ đầu đến cuối với một kiến trúc hoàn toàn mới được, thế nên mình chọn cách sử dụng một kiến trúc sẵn có, đó là MobileNetV3.
MobileNet là một dòng neural network được thiết kế để có thể hoạt động tốt trên các thiết bị low-end như chạy trên CPU, trên mobile,... nhưng vẫn đảm bảo tính chính xác và tốc độ cao.
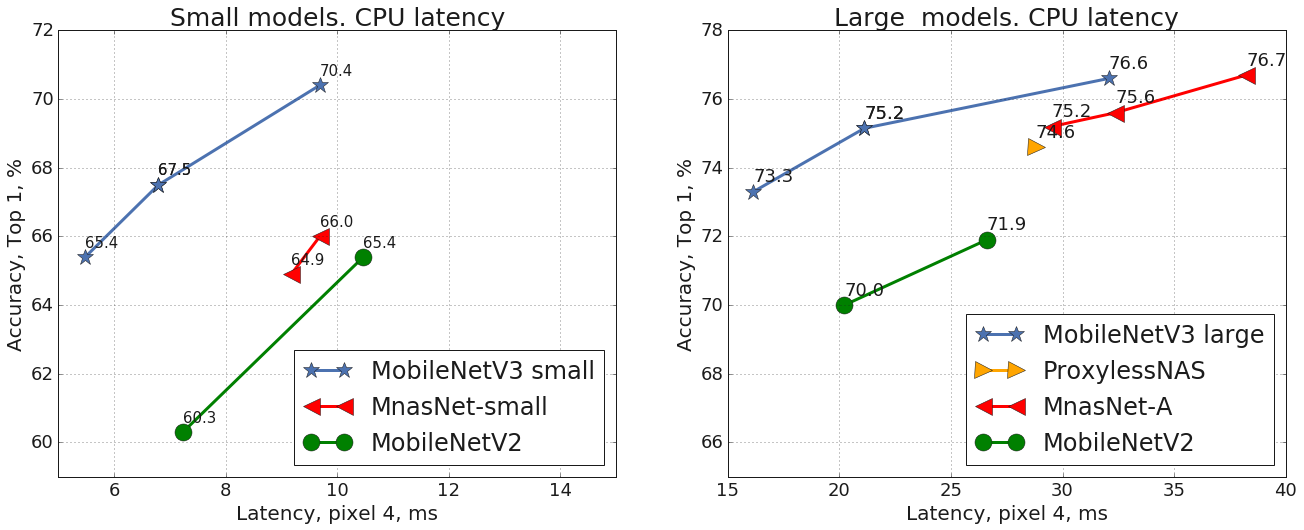
MobileNetV3 có 2 phiên bản, Large và Small, khác biệt nhau về độ chính xác (accuracy) và tốc độ xử lý (latency), như sơ đồ trên. Ở đây, vì yêu cầu về tốc độ nên mình chọn sử dụng MobileNetV3 Small.
Finetune MobileNetV3
Cũng giống như model vision-based transformer ở trên, phiên bản pre-trained của MobileNetV3 cũng support phân loại khoảng 1000 labels khác nhau. Đối với feature mà chúng ta đang xây dựng, thì model chỉ cần nhận diện một hình ảnh có dạng của một chiếc invoice hoặc là không, tức là chỉ cần 2 label: valid và invalid.
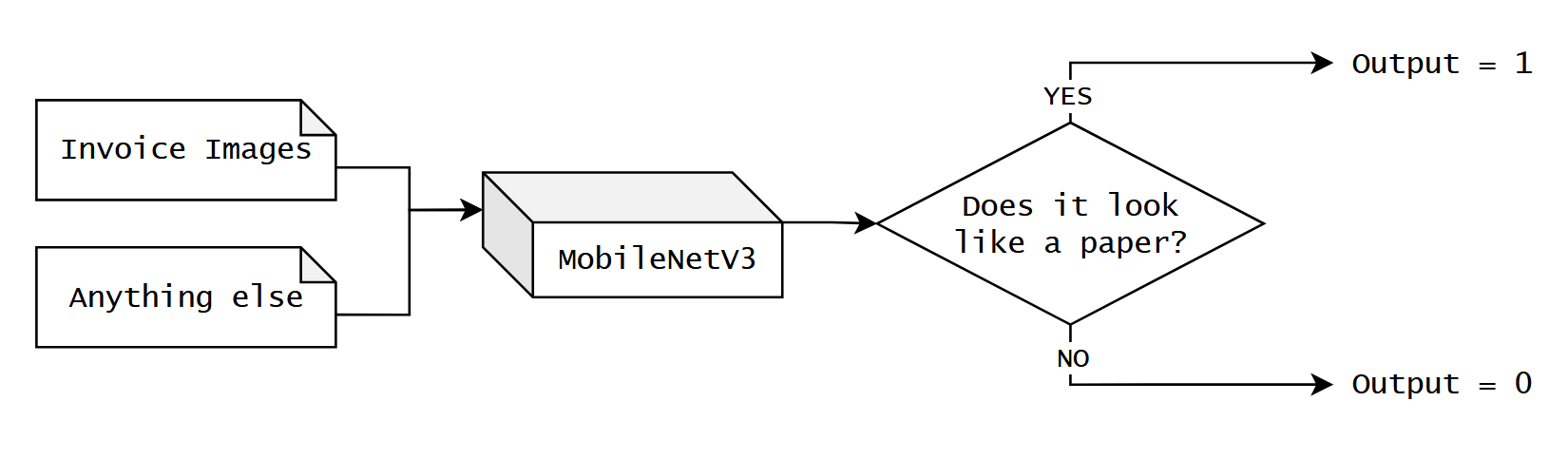
Để tiết kiệm thời gian, chúng ta sẽ dùng 2 bộ dữ liệu có sẵn từ Hugging Face cho 2 label này:
- Đối với tập
valid, chúng ta dùng bộ dữ liệu dajor85570/invoices-and-receipts_ocr_v1, đây là tập hình ảnh về invoice/receipt, giúp cho model nhận biết được thế nào là một chiếc invoice hợp lệ. - Đối với tập
invalid, chúng ta cần đưa vào tất cả các thể loại hình ảnh, miễn nó không có dạng của một chiếc invoice, vì thế mình sử dụng bộ dữ liệu pouya-haghi/imagenet-subset, đây là một tập con của bộ dữ liệu ImageNet, thường được dùng để train model nhận diện đủ các thể loại hình ảnh khác nhau.
Vì kích thước của 2 tập dữ liệu khác nhau, mình sẽ load tầm 2000 hình cho mỗi một tập dữ liệu.
from datasets import load_dataset
# Load "valid" class: invoices and receipts (paper-like documents)
valid_dataset = load_dataset(
"dajor85570/invoices-and-receipts_ocr_v1",
split="train"
)
# Load "invalid" class: general images from ImageNet
invalid_dataset = load_dataset(
"pouya-haghi/imagenet-subset",
split="train"
)
valid_images = [item["image"] for item in valid_dataset.select(range(2000))]
invalid_images = [item["image"] for item in invalid_dataset.select(range(2000))]
print(f"Dataset: {len(valid_images)} valid + {len(invalid_images)} invalid")
Tiếp theo là khởi tạo model, vì thư viện torchvision đã có sẵn implementation của model MobileNetV3, chúng ta không cần phải implement lại model này từ đầu.
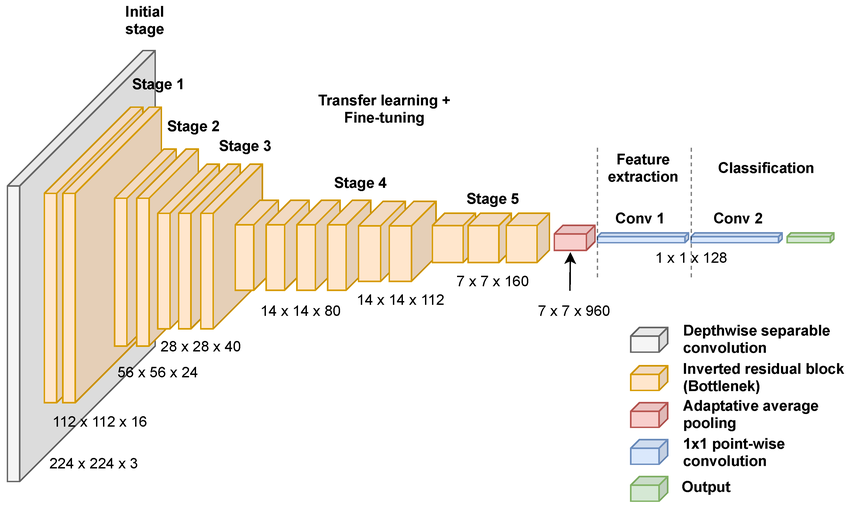
Mục đích của chúng ta là thay đổi cách model thực hiện bước phân loại, thay vì output ra 1000 labels khác nhau thì chúng ta chỉ cần output 2 labels, nên chúng ta cần phải freeze các layer phía trước, và chỉ cần update layer classification của model.
import torch.nn as nn
from torchvision.models import mobilenet_v3_small, MobileNet_V3_Small_Weights
# Load pretrained MobileNetV3-Small (trained on ImageNet's 1000 classes)
model = mobilenet_v3_small(weights=MobileNet_V3_Small_Weights.IMAGENET1K_V1)
# Freeze the learned features
for param in model.features.parameters():
param.requires_grad = False
# Update the classifier head for binary classification
in_features = model.classifier[0].in_features
num_labels = 2 # two labels: [0 (invalid), 1 (valid)]
model.classifier = nn.Sequential(
nn.Linear(in_features, 1024),
nn.Hardswish(),
nn.Dropout(p=0.2),
nn.Linear(1024, num_labels),
)
Sau đó gộp chung 2 bộ dữ liệu đã load ở trên, gắn label tương ứng và bắt đầu train:
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
# This function preprocess each input image data into the right
# format for MobileNetV3
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
class BinaryDataset(Dataset):
def __init__(self, valid_imgs, invalid_imgs, transform):
self.samples = valid_imgs + invalid_imgs
# Label 1 = valid (paper-like), Label 0 = invalid (everything else)
self.labels = [1]*len(valid_imgs) + [0]*len(invalid_imgs)
self.transform = transform
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
image = self.samples[idx].convert("RGB")
return self.transform(image), self.labels[idx]
# Create dataloader
dataset = BinaryDataset(valid_images, invalid_images, transform)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# Training loop
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
num_epochs = 10
for epoch in range(num_epochs):
for images, labels in dataloader:
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Đoạn code trên được train với 10 epochs, có nghĩa run qua tất cả các rows trong bộ dữ liệu training 10 lần.
Sau khi train, chúng ta sẽ có một model với kích thước chỉ 6MB, có khả năng nhận vào một hình ảnh và nhận diện xem, tấm hình đó có dạng của một chiếc invoice hay không, kết quả output là 0 (invalid) hoặc 1 (valid).
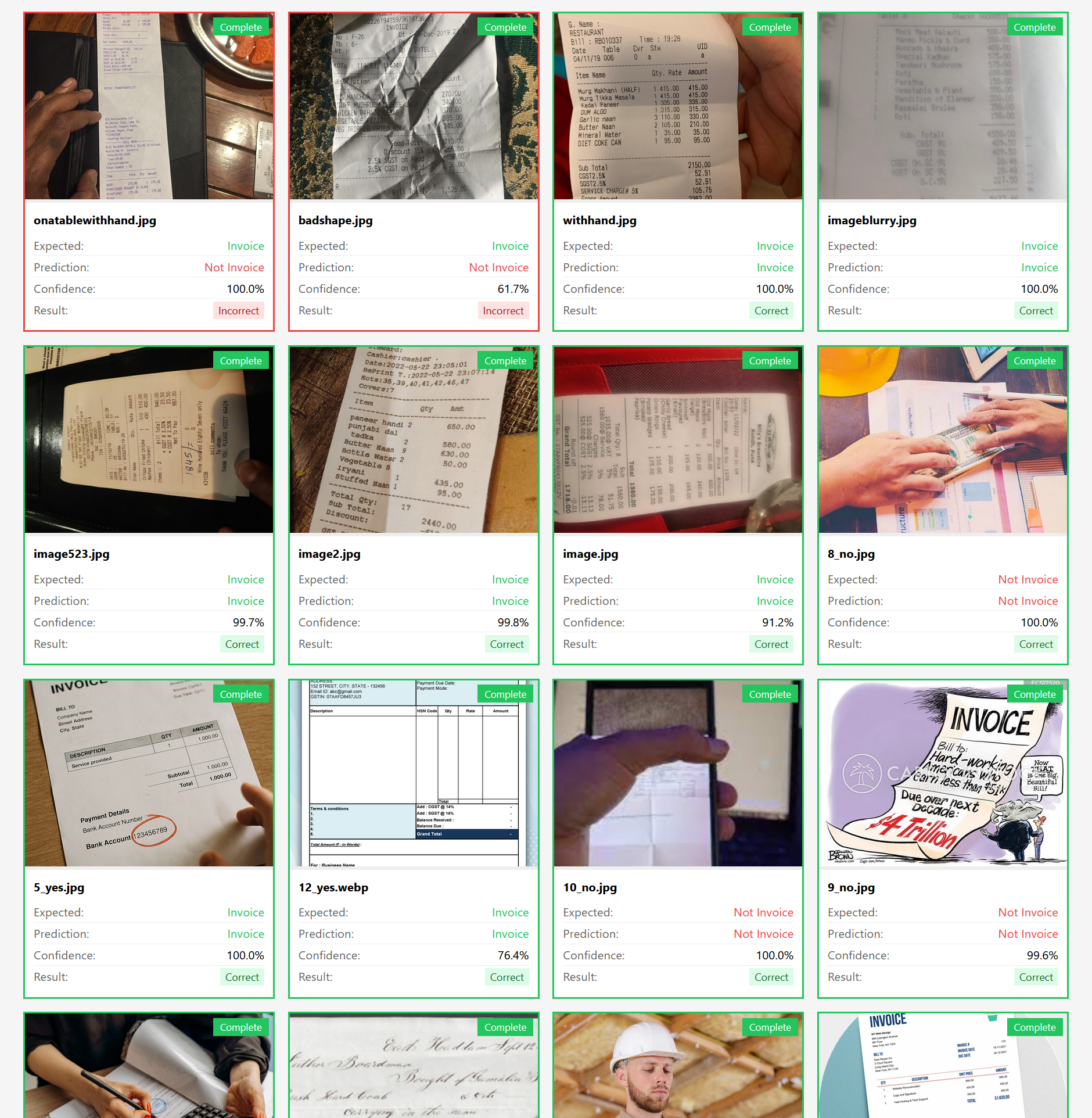
So với model có sẵn ở phần trước, chúng ta có thể thấy model nhận diện tốt hơn, những ví dụ mà ở phần trước bị nhận nhầm là invoice như hình chụp màn hình chiếc điện thoại, hoặc mẫu truyện tranh đã được model mới xác định là không phải invoice.
Có một vài trường hợp model mới nhận diện sai, ví dụ 2 tấm hình đầu trong screenshot, một hình có tờ invoice quá dài, một hình có tờ invoice bị nhàu nát, lý do là vì trong tập dữ liệu input chúng ta không có 2 trường hợp này. Và để cải thiện, chúng ta chỉ cần bổ sung thêm vài chục hình example cho mỗi trường hợp (nghe vẫn đáng tin cậy hơn là ngồi thêm/bớt label, đúng không?).
Tất nhiên, đây chỉ là một thử nghiệm nhỏ, nên những thông số mình đề cập đến trong bài như kích thước bộ dữ liệu, num_epochs hay model size,... đều chỉ dừng lại ở quy mô nhỏ. Để triển khai được mô hình này trong thực tế, thì chúng ta cần phải tiến hành thử nghiệm, tinh chỉnh một cách khoa học hơn rất nhiều. Trên thực tế thì dự án này đã không được công ty approve cho mình tiếp tục phát triển, vì lý do kinh phí và kinh nghiệm, nên giờ mình viết bài kể lể ở đây cho đỡ tiếc công vậy thôi